

Prérequis
- Vous avez un cluster Proxmox VE d’au moins 3 nœuds en mode HCI avec Ceph
- Vous désirez ajouter un réseau de stockage (cluster network) pour booster les performances de Ceph
- Vous pouvez dédier 2 interfaces réseau sur chacun des nœuds pour faire des liens directs entre les nœuds (mesh)
Introduction
Si vous lisez ces pages, les bénéfices d’un réseau «full mesh» pour vos OSD (object storage daemons) et pour les live migrations de vos VMs n’est plus à démontrer. En quelques mots, si les bénéfices en bande passante dépendent de votre réseau principal, les bénéfices en latence pour les OSD sont en revanche importants. En effet si vous utilisez vos switches en «store-and-forward» par défaut et que vous ne pouvez pas activer le mode «cut-through» disponible sur les switches haut de gamme, vous pouvez gagner plus de 100µs en latence. De plus, avoir un réseau dédié aux OSD est recommandé pour avoir des performances correctes et pour pouvoir aller en production avec Ceph, et tant mieux si Proxmox VE peut aussi en bénéficier. Ici, on ne parle pas seulement d’un réseau dédié aux OSD, mais également d’un maillage complet «Full Mesh», c’est à dire que tous les nœuds sont connectés entre eux.
«Full Mesh» signifie également qu’il y a des chemins redondants, il faut donc les gérer. Ici on utilisera OSPF avec Free Range Router (Anciennement Zebra puis Quagga)
Ce post est fortement inspiré de l’excellent article de John W Kerns : Proxmox/Ceph – Full Mesh HCI Cluster w/ Dynamic Routing
Les différences par rapport à cet article :
- Le Proxmox VE (PVE) était déjà configuré en HCI + Ceph sur 3 nœuds. (Liens en vert sur le diagramme ci dessous)
- Je ne suis pas parvenu à utiliser IPV6 Only pour le réseau de stockage. (c.f. Request on Ceph Support) Ç’aurait été tellement plus pratique de ne pas devoir définir chaque lien en IPV4 avec des masques de sous réseau /30.
Diagramme

Configuration
Je suppose que vous comprenez les bases de la configuration réseau sous Linux, et je ne vais pas aller dans tous les détails.
1. Configurez chaque lien en IPv4
Vous pouvez utiliser un Subnet Calculator pour vous aider en choisissant des /30. J’ai pris les 3 premiers :

Sur chaque nœud :
- Configurez une IP de loopback additionelle et unique. Leurs routes seront propagées par FRR.
J’ai choisi des IPs de la range : 192.168.68.128/25 :- 192.168.68.129/32 pour pve1
- 192.168.68.130/32 pour pve2
- 192.168.68.131/32 pour pve3
- Configurez les «Start Address» et «End Address» à chaque extrémité de chacun des 3 liens. Exemple sur pve1, le début de votre fichier /etc/network/interfaces doit ressembler à ceci :
auto lo
iface lo inet loopback
iface lo:0 inet static
address 192.168.68.129/32
auto enp2s0
iface enp2s0 inet manual
# Link to pve1-pve3
auto enp3s0
iface enp3s0 inet manual
address 192.168.68.1/30
# Link to pve1-pve2
auto enx00e04c680015
iface enx00e04c680015 inet manual
address 192.168.68.5/30
Redémarrez le réseau :
systemctl restart networking.service
Testez chaque lien avec la commande ping depuis le nœud distant. Par exemple depuis pve3 :
ping 192.168.68.1
2. Installez les logiciels requis
Tout est dans la distribution Debian de Proxmox VE. À exécuter sur chaque nœud.
apt install frr-pythontools/stable # Installera également le package frr apt install iptraf-ng/stable # Vous permettra de monitorer les flux réseaux sur les interfaces plus tard
3. Configurez FRR
- Activez l’OSPF en le mettant à
=yesdans/etc/frr/daemons(ne changez rien d’autre) - Redémarrez FRR :
systemctl restart frr.service
Adaptez l’exemple de configuration ci dessous pour chaque nœud.
- Mettez un router-id différent sur chaque nœud. (j’ai choisi .1, .2 et .3)
- Adaptez les noms d’interfaces
ip forwarding ! router ospf ospf router-id 0.0.0.1 log-adjacency-changes exit ! interface lo ip ospf area 0 exit ! interface enp3s0 ip ospf area 0 ip ospf network point-to-point exit ! interface enx00e04c680015 ip ospf area 0 ip ospf network point-to-point exit !
- Pour configure l’OSPF, entrez dans le shell du routeur (comme sur un routeur Cisco) avec la commande
vtysh - tapez
configpour entrer en mode configuration. - Copiez-collez la configuration dans le terminal
exitpour sortir du mode de configurationwritepour enregistrer la configurationexitpour sortir du vtysh, mais vous pouvez rester dans le vtysh car vous allez utiliser la commandeshow ip ospf neighborpour voir apparaître les nœuds voisins au fur et à mesure que vous les configurez.
Exemple sur pve1 :
pve1# show ip ospf neighbor Neighbor ID Pri State Up Time Dead Time Address Interface RXmtL RqstL DBsmL 0.0.0.3 1 Full/- 6m15s 34.763s 192.168.68.2 enp3s0:192.168.68.1 0 0 0 0.0.0.2 1 Full/- 6m16s 33.360s 192.168.68.6 enx00e04c680015:192.168.68.5 0 0 0
Vous pouvez ensuite sortir de vtysh avec exit.
Ensuite, vérifiez les routes au niveau de l’OS:
root@pve1:~# ip route list proto ospf
192.168.68.8/30 nhid 76 metric 20
nexthop via 192.168.68.2 dev enp3s0 weight 1
nexthop via 192.168.68.6 dev enx00e04c680015 weight 1
192.168.68.130 nhid 77 via 192.168.68.6 dev enx00e04c680015 metric 20
192.168.68.131 nhid 72 via 192.168.68.2 dev enp3s0 metric 20
root@pve1:~#
Le plus important ici sont les IPs 192.168.68.130 et 192.168.68.131 (la 192.168.68.129 n’est pas listée puisqu’elle est locale à pve1)
Désactivez les liens un à un pour vérifier que l’OSPF converge bien, et que les 3 IPs de loopback sont toujours accessibles depuis tous les nœuds.
Si vous avez Ansible et que vous avez un groupe défini avec vos PVEs, utilisez une commande comme ci-dessous depuis votre workstation. Sinon, exécutez le one-liner en argument de bash sur chaque serveur :
$ansible pve -a '/bin/bash -c "for ip in 192.168.68.{129..131}; do ping -c1 -W1 $ip > /dev/null && echo OK || echo ERROR; done;"'
pve3 | CHANGED | rc=0 >>
OK
OK
OK
pve1 | CHANGED | rc=0 >>
OK
OK
OK
pve2 | CHANGED | rc=0 >>
OK
OK
OK
22:43:13[Z690-seashell-129886][pivert] /workdir
$ansible pve -a 'ip route list proto ospf'
pve2 | CHANGED | rc=0 >>
192.168.68.0/30 nhid 64 metric 20
nexthop via 192.168.68.10 dev enp2s0 weight 1
nexthop via 192.168.68.5 dev enp3s0 weight 1
192.168.68.129 nhid 65 via 192.168.68.5 dev enp3s0 metric 20
192.168.68.131 nhid 40 via 192.168.68.10 dev enp2s0 metric 20
pve3 | CHANGED | rc=0 >>
192.168.68.4/30 nhid 127 metric 20
nexthop via 192.168.68.9 dev enp3s0 weight 1
nexthop via 192.168.68.1 dev enp2s0 weight 1
192.168.68.129 nhid 128 via 192.168.68.1 dev enp2s0 metric 20
192.168.68.130 nhid 100 via 192.168.68.9 dev enp3s0 metric 20
pve1 | CHANGED | rc=0 >>
192.168.68.8/30 nhid 76 metric 20
nexthop via 192.168.68.2 dev enp3s0 weight 1
nexthop via 192.168.68.6 dev enx00e04c680015 weight 1
192.168.68.130 nhid 77 via 192.168.68.6 dev enx00e04c680015 metric 20
192.168.68.131 nhid 72 via 192.168.68.2 dev enp3s0 metric 20
4. Modifiez la configuration de Ceph sur un seul nœud
Le /etc/ceph/ceph.conf est en effet un lien symbolique vers le ceph.conf dans le pxmcfs monté sous /etc/pve. Il n’y a donc besoin de faire la modification que sur un seul nœud. (Si vous ne connaissiez pas déjà pxmcfs je vous conseille de suivre le lien et de le lire, c’est le cœur du cluster Proxmox VE, et vous pouvez l’utiliser pour vos (petits) fichiers de configuration.)
Il n’y a que 1 lignes à modifier (ou ajouter) dans la section [global] :
Ajoutez le cluster_network pour lui indiquer le réseau contenant toutes les IPs de loopback.cluster_network = 192.168.68.128/25
La section [global] de votre /etc/ceph/ceph.conf devrait ressembler à ceci. (De mémoire, j’avais ajouté les osd_pool_default_xxx à la création du cluster pour ne pas avoir à les re-spécifier à la création des pools ceph – il se peut que vous ne les ayez pas)
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
public_network = 192.168.178.0/24
cluster_network = 192.168.68.128/25
fsid = e7628d51-xxxx-xxxx-xxxx-xxxxxxxxxxx
mon_allow_pool_delete = true
mon_host = 192.168.178.2 192.168.178.4 192.168.178.3
osd_pool_default_min_size = 2
osd_pool_default_size = 3
Remarque : j’ai laissé les mon_host sur le réseau externe car :
- Le Ceph est également accédé par des hosts externes à Proxmox VE et par certaines VMs qui montent une partie du CephFS
- Les ceph-mon n’écoutent que sur une seule IP
- La majorité de la bande passante est consommée par les
ceph-osd, et non les autres processus (ceph-mon,ceph-mgretceph-mdssi vous utilisez CephFS)
Attention maintenant. Au redémarrage des démons ceph, ils seront injoignables tant que les démons des 3 serveurs n’auront pas redémarrés.
Si vous voulez éviter un rebalancing des PG (placement groups) ou si vous comptez isoler votre nœud pendant plusieur minutes, vous pouvez :
ceph osd set noout ceph osd set norebalance
Ou via «Manage Global Flags» dans le GUI
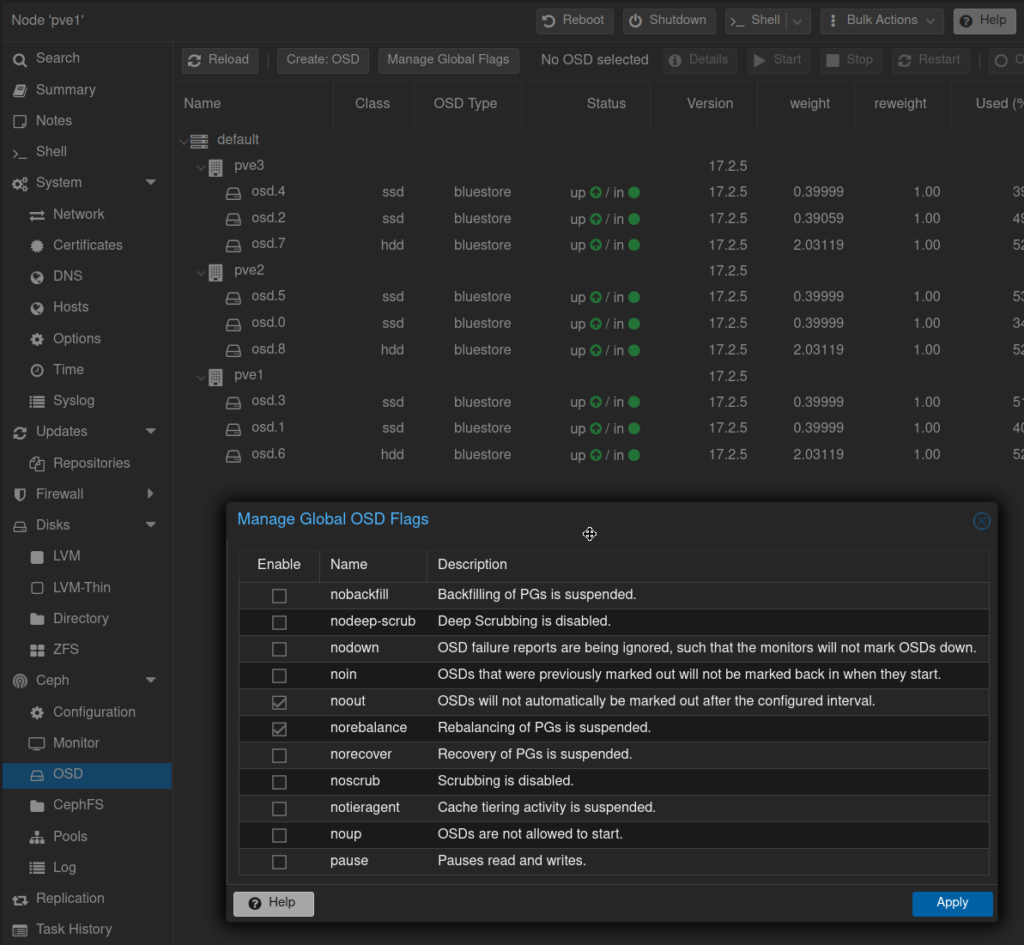
Mais n’oubliez pas d’enlever ces flags (unset) une fois le cluster reconfiguré. Le GUI vous le rappellera :
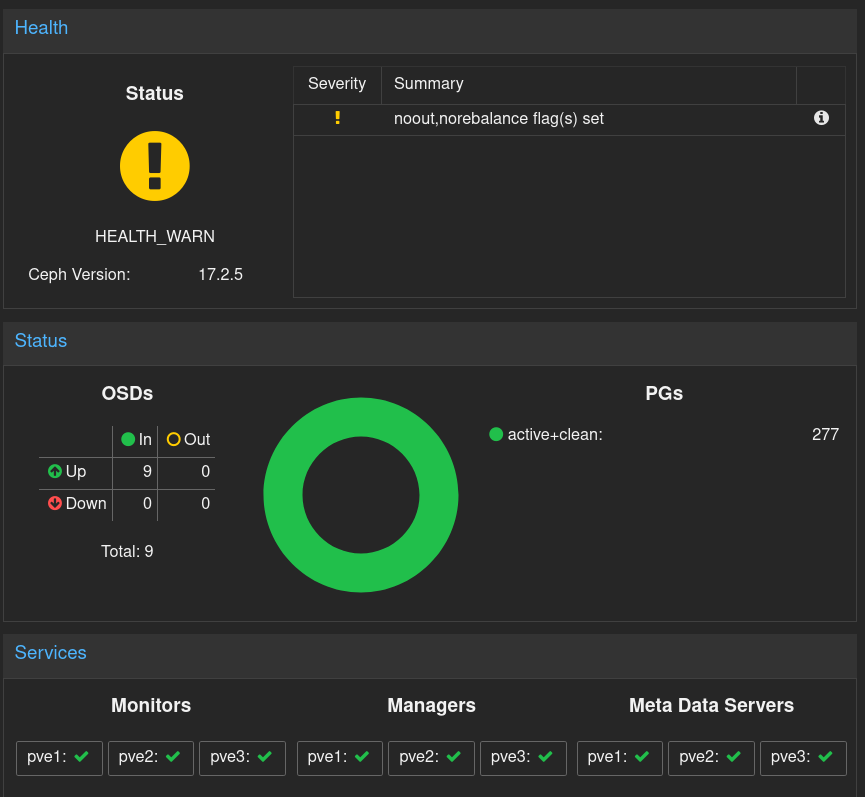
Je vous conseille de d’abord essayer un redémarrage sur un nœud ça mettra juste votre Ceph en dégradé si vous avez bien un osd_pool_default_min_size à au moins 2 pour chaque pool.
Une option si c’est possible est d’éteindre tout ce qui utilise Ceph et d’éteindre Ceph. Puis de les démarrer un à un. Le risque d’avoir ceph indisponible pendant la manipulation est donc très élevé, mais si ça passe bien sur un nœud, ça devrait être très court.
Une autre option est d’attendre le redémarrage des nœuds à l’étape suivante, mais ç’aura comme inconvénient que le premier nœud devra démarrer sans Ceph, et faudra donc le redémarrer une seconde fois à la fin si vous dépendez de Ceph.
systemctl restart ceph.target
Après redémarrage, vérifiez que seuls les ceph-osd écoutent sur l’IP externe ET l’IP interne, les autres processus doivent écouter sur les interfaces externes.
root@pve1:~# lsof -Pni | grep 'ceph-.*LIST' | sort -k 9 ceph-mon 2460 ceph 14u IPv4 38058 0t0 TCP 192.168.178.2:3300 (LISTEN) ceph-mon 2460 ceph 16u IPv4 38059 0t0 TCP 192.168.178.2:6789 (LISTEN) ceph-mds 2458 ceph 18u IPv4 31347 0t0 TCP 192.168.178.2:6800 (LISTEN) ceph-mds 2458 ceph 19u IPv4 31349 0t0 TCP 192.168.178.2:6801 (LISTEN) ceph-osd 2875 ceph 18u IPv4 32456 0t0 TCP 192.168.178.2:6802 (LISTEN) ceph-osd 2870 ceph 18u IPv4 40060 0t0 TCP 192.168.178.2:6803 (LISTEN) ceph-osd 2875 ceph 19u IPv4 32461 0t0 TCP 192.168.178.2:6804 (LISTEN) ceph-osd 2870 ceph 19u IPv4 40066 0t0 TCP 192.168.178.2:6805 (LISTEN) ceph-osd 2875 ceph 22u IPv4 32472 0t0 TCP 192.168.178.2:6806 (LISTEN) ceph-osd 2870 ceph 22u IPv4 40080 0t0 TCP 192.168.178.2:6807 (LISTEN) ceph-osd 2875 ceph 23u IPv4 32481 0t0 TCP 192.168.178.2:6808 (LISTEN) ceph-osd 2870 ceph 23u IPv4 40090 0t0 TCP 192.168.178.2:6809 (LISTEN) ceph-osd 2974 ceph 18u IPv4 36336 0t0 TCP 192.168.178.2:6810 (LISTEN) ceph-osd 2974 ceph 19u IPv4 36348 0t0 TCP 192.168.178.2:6811 (LISTEN) ceph-osd 2974 ceph 22u IPv4 36380 0t0 TCP 192.168.178.2:6812 (LISTEN) ceph-osd 2974 ceph 23u IPv4 39301 0t0 TCP 192.168.178.2:6813 (LISTEN) ceph-mgr 2459 ceph 24u IPv4 40372 0t0 TCP 192.168.178.2:6814 (LISTEN) ceph-mgr 2459 ceph 32u IPv4 40388 0t0 TCP 192.168.178.2:6815 (LISTEN) ceph-osd 2875 ceph 20u IPv4 32462 0t0 TCP 192.168.68.129:6800 (LISTEN) ceph-osd 2870 ceph 20u IPv4 40068 0t0 TCP 192.168.68.129:6801 (LISTEN) ceph-osd 2875 ceph 21u IPv4 32465 0t0 TCP 192.168.68.129:6802 (LISTEN) ceph-osd 2870 ceph 21u IPv4 40072 0t0 TCP 192.168.68.129:6803 (LISTEN) ceph-osd 2875 ceph 24u IPv4 32486 0t0 TCP 192.168.68.129:6804 (LISTEN) ceph-osd 2875 ceph 25u IPv4 32492 0t0 TCP 192.168.68.129:6805 (LISTEN) ceph-osd 2870 ceph 24u IPv4 40097 0t0 TCP 192.168.68.129:6806 (LISTEN) ceph-osd 2870 ceph 25u IPv4 40105 0t0 TCP 192.168.68.129:6807 (LISTEN) ceph-osd 2974 ceph 20u IPv4 36357 0t0 TCP 192.168.68.129:6808 (LISTEN) ceph-osd 2974 ceph 21u IPv4 36367 0t0 TCP 192.168.68.129:6809 (LISTEN) ceph-osd 2974 ceph 24u IPv4 39312 0t0 TCP 192.168.68.129:6810 (LISTEN) ceph-osd 2974 ceph 25u IPv4 39324 0t0 TCP 192.168.68.129:6811 (LISTEN) ceph-mgr 2459 ceph 39u IPv6 48635 0t0 TCP *:8443 (LISTEN) ceph-mgr 2459 ceph 37u IPv4 36855 0t0 TCP *:9283 (LISTEN)
Remarque: Le processus ceph-mon écoute sur 2 ports :
- 6789 Messenger V1 Protocol
- 3300 Messenger V2 Protocol ou msgr2 (Depuis Quincy de mémoire) – Important si vous utilisez le nouveau client CSI pour Kubernetes qui n’utilisent que le protocole V2. (J’avais mis du temps à comprendre que mon driver CSI ne pouvait initialiser les PV claims K8S à cause du firewall qui filtrait ce port. c.f. Ceph CSI on Kubernetes)
5. Modifiez les /etc/hosts
Cette étape n’est pas nécessaire, mais va permettre à Proxmox d’utiliser le «cluster network» pour les migrations de VMs.
Cette modification va également générer des interruptions de service Proxmox, et un redémarrage de tous les nœuds.
Sur chaque nœud, modifiez les entrées statiques qui pointent vers les membres du cluster pour qu’elles utilisent le réseau de stockage routé par OSPF.
Exemple (avec les anciennes lignes en commentaires) :
root@pve1:~# cat /etc/hosts 127.0.0.1 localhost.home.pivert.org localhost # 192.168.178.2 pve1.pivert.org pve1.home.pivert.org pve1 # 192.168.178.3 pve2.pivert.org pve2.home.pivert.org pve2 # 192.168.178.4 pve3.pivert.org pve3.home.pivert.org pve3 192.168.68.129 pve1.pivert.org pve1.home.pivert.org pve1 192.168.68.130 pve2.pivert.org pve2.home.pivert.org pve2 192.168.68.131 pve3.pivert.org pve3.home.pivert.org pve3
Monitoring
Voilà, c’est déjà fini 😉
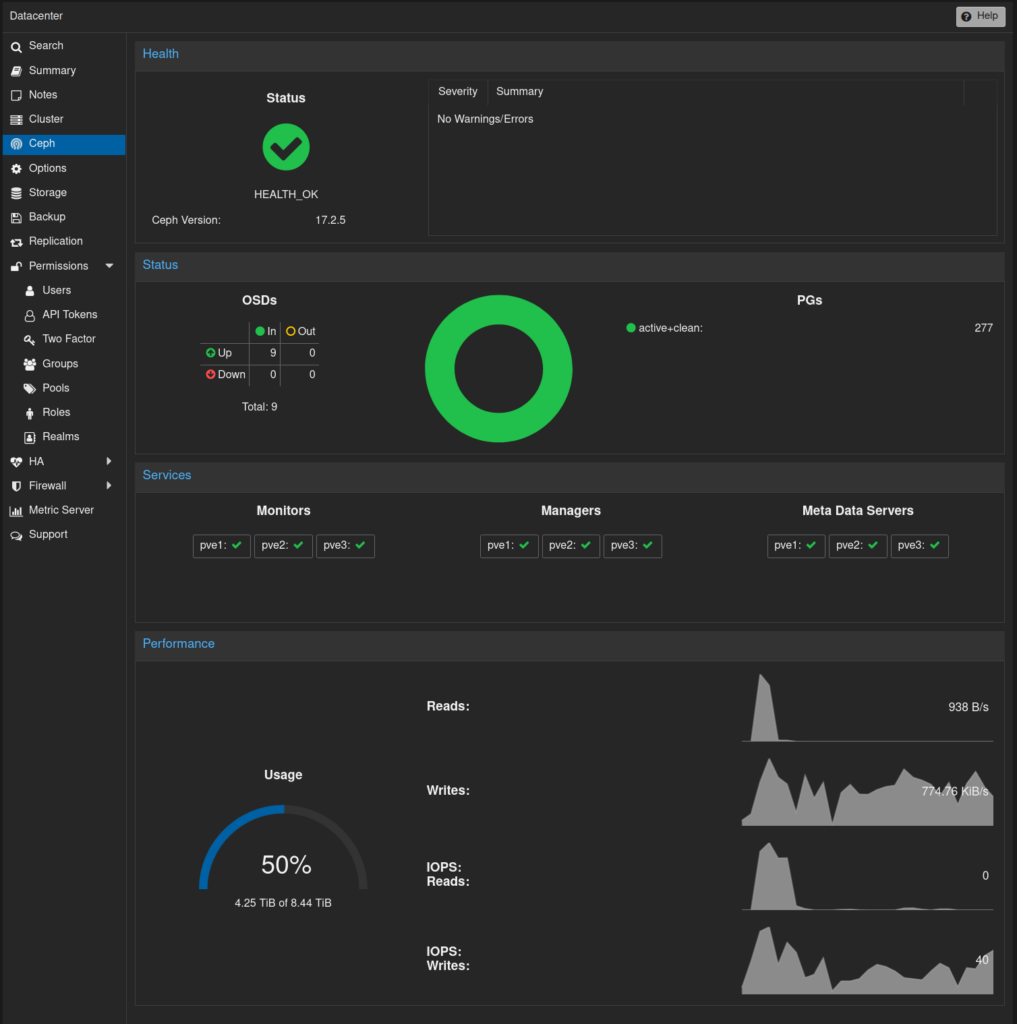
Monitorez votre cluster, assurez-vous que les clusters Proxmox et Ceph soient bien «healthy», et que tous les OSDs soient bien UP et IN. Redémarrez les services ceph ou les nœuds en cas de problème. Vous aurez peut-être un OSD ou un MON qui va crasher lors de la modification, mais il suffit de le redémarrer, et d’archiver le «crash report» pour qu’il disparaisse des warnings. Quelques commandes utiles :
ceph status ceph crash ls # Regardez si il y a une * dans la colonne NEW. Si c'est le cas il faudra l'archiver : ceph crash archive-all lsof -Pni
Le GUI est plus pratique, mais vous pouvez aussi monitorer votre PVE Cluster Manager depuis la console :
root@pve1:~# pvecm status
Cluster information
-------------------
Name: pve
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Mon May 1 01:24:07 2023
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000001
Ring ID: 1.b75
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 192.168.178.2 (local)
0x00000002 1 192.168.178.3
0x00000003 1 192.168.178.4
Il vous reste à mettre de la charge sur Ceph, et faire des live migrations de grosses VM, et monitorez le traffic avec iptraf -g
Remarques
- J’ai pris l’exemple de Full Mesh sur 3 noeuds. Il faut donc 2 ports réseau disponibles. Mais c’est applicable à d’autre cas. Il suffit d’appliquer la formule n = (i-1)(h+1) avec n le nombre de nœuds, i le nombre d’interfaces, et h le nombre de hop maximum entre deux nœuds. Ici, 2 interfaces, et 0 hop (full mesh) : (2+1)1 = 3 nœuds connectables en full mesh.
Si vous avez 4 interfaces réseau pour le réseau de stockage, et que vous acceptez un max hop de 1, vous pouvez monter un half-mesh de 25 nœuds : (4+1)2=25. Le half-mesh perd de son intérêt pour la latence, mais peut vous faire économiser beaucoup sur les switch réseau si vous êtes en plus de 25 Gbits avec des Switch. - Je n’avais jamais fait cette modification car j’avais peur de la réaction de Proxmox VE et de Ceph. Mais la semaine dernière, j’avais besoin d’un LAB de démo PVE + «Full Mesh» lors d’un Hackathon. C’était l’occasion. Les serveurs ne disposant que de 2 interfaces onboard, j’ai ajouté des adaptateurs USB GE pour la connexion au réseau externe. Nous avons rencontré 3 problèmes :
- Même si très élégante, la solution IPV6 pour le «cluster network» n’a pas fonctionné, car les OSD cherchent une IPv4 tant qu’il n’est pas désactivé. (c.f. Reported Ceph Issue).
- Les adaptateurs USB 1GbE génèrent de la latence et du jitter. Test avec un
ping -s1000 -c100:- Via l’interface onboard:
— pve3.pivert.org ping statistics —
100 packets transmitted, 100 received, 0% packet loss, time 101327ms
rtt min/avg/max/mdev = 0.110/0.190/0.791/0.131 ms - Via l’interface USB:
— pve2.pivert.org ping statistics —
100 packets transmitted, 100 received, 0% packet loss, time 101327ms
rtt min/avg/max/mdev = 0.233/0.425/2.388/0.211 ms
- Via l’interface onboard:
- Une des interface USB disparaissait au bout de 10 minutes avec le message kernel ‘Stop submitting intr, status -71‘. La solution de désactiver le power management avec usbcore.quicks pour ce device USB semble avoir réglé le problème pour certaines, :
root@pve1:~# cat /etc/default/grub | grep GRUB_CMDLINE_LINUX_DEFAULT GRUB_CMDLINE_LINUX_DEFAULT="quiet usbcore.quirks=0bda:8153:k delayacct"
P.S.: le delayacct est utile si vous voulez également utiliser iotop pour monitorer les IOs.
Complément 06/2023
- Il semble que le problème de la perte de connexion avec les RTL8152 USB ne soit pas complètement résolu. J’ai fini par remplacer cet adaptateur réseau.
- En changeant le /etc/hosts, les copies de RAM lors des migrations de VM passent bien par le «cluster network», mais le cluster PVE reste configuré via les interfaces externes. Je regarderai plus tard comment réaliser ce 3è changement. Sinon il faudra quitter et rejoindre le cluster pour chaque nœud séquentiellement.
Complément 09/2023
- Exception faite de la latence supplémentaire, les nouveaux adaptateurs réseau USB fonctionnent à merveille, bien que toujours basés sur le RTL8152. Il y avait un très faible taux de RX Drop Packets (0.01%) qui n’affectait pas le traffic. Ce problème a été résolu dans la mise à jour de ProxmoxVE de fin juillet.
- Malgré la petite bande passante pour Ceph (1Gb/s), le full mesh a changé la donne. C’est performant, et le goulot d’étranglement se situe maintenant au niveau des SSDs NVME. Je recommande de toujours sélectionner des versions “Pro” avec des IOPS constantes et une bonne endurance (high TBW), même si vous estimez un usage faible ou moyen de Ceph. La bonne réactivité du réseau pousse à demander plus à Ceph, et le second goulot d’étranglement peut être la quantité de RAM disponible pour Ceph: 12 à 16GB / OSD sont à prévoir.
5 responses to “Comment ajouter un Cluster Network «Full-Mesh» à Ceph sur Proxmox VE”
Merci pour ce magnifique article !
J’ai une remarque: iptraf ne me montre pas le traffic sur lo:0 (j’ai testé avec iperf3)
mon commentaire est idiot, merci de ne pas le prendre en compte, la bande passante ne passera jamais sur lo, mais sur une des interfaces configurée en ospf…
J’ai fait le full-mesh à 2,5G (en lieu et place d’un bonding sur le réseau public à 2×2,5G + 1G) et ceph va beaucoup, beaucoup, beaucoup mieux !
Dans ton cas, je pense que le goulot d’étranglement se situe davantage au nveau du réseau: 1Gbits/s n’est clairement pas suffisant, surtout avec des NVME !
Concernant la RAM, pour info, je suis passé à 8Go/OSD (disques de 4To), et mes OSD ne dépassent pas 5Go d’utilisation.
Magnifique !!
Dans mon cas, j’avais donné 16GB en osd_memory_target, et au final ils montent jusqu’à 20GB d’utilisation dans htop tree mode. L’interface Proxmox reporte 30GB, ce chiffre semble erroné.
Je suis repassé à des valeurs plus sobres de 8GB:
ceph config set osd osd_memory_target 8589934592
En HCI, Ceph recommande 20% de RAM pour les OSDs.
Le monitoring ne montre quasiment jamais de débits au delà de 20MB/s sur les interfaces du storage network en utilisation standard (hors rebalance), par contre, le NVMe montre une utilisation de 100% déjà avec du 30MB écriture + 15MB en lecture; parfois plus de 50% d’utilisation avec seulement 2MB/s.. J’utilise des Crutial CT4000P3SSD8 et du vieux PCIe 3.0 sur des MiniPC à 400€. Le bottleneck c’est soit le SSD, soit le manque de lignes PCI sur la carte-mère. Avant de saturer les liens GbE, il y a d’autres choses… C’est un ensemble. Pour faire mieux il faut tout upgrader. Avec des connecteurs M.2 qui ont 4 lanes PCIe 5 dédiées et des NVMe qui assurent… Mais malgré les limitations, le cluster fonctionne admirablement bien, et pour une consommation électrique ridicule.
le créateur de la chaine youtube (EN) “apalrd’s adventures” a sorti le 16-03-23 une vidéo (+ un article sur son site web) sur la mise en place d’un Proxmox Full-MeshIPV6 plus complète que l’article de John N Kerns
https://www.youtube.com/watch?v=dAjw_4EpQdk
https://www.apalrd.net/posts/2023/cluster_routes/